Cointegration and Error Correction
Definition: If there exists a stationary linear combination of
nonstationary random variables, the variables combined are said to be cointegrated.

|

|
The old woman and
the boy are unrelated to one another, except that they are both on a random walk in the
park. Information about the boy's location tells us nothing about the old woman's
location. |

|
The old man and the
dog are joined by one of those leashes that has the cord rolled up inside the handle on a
spring. Individually, the dog and the man are each on a random walk.
They cannot wander too far from one another because of the leash. We say that
the random processes describing their paths are cointegrated. |
The notion of cointegration arose out of the concern about spurious or
nonsense regressions in time series. Specifying a relation in terms of levels of the
economic variables, say 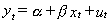 , often produces
empirical results in which the R2 is quite high, but the Durbin-Watson
statistic is quite low. This happens because economic time series are dominated by smooth,
long term trends. That is, the variables behave individually as nonstationary random
walks. In a model which includes two such variables it is possible to choose
coefficients which make
, often produces
empirical results in which the R2 is quite high, but the Durbin-Watson
statistic is quite low. This happens because economic time series are dominated by smooth,
long term trends. That is, the variables behave individually as nonstationary random
walks. In a model which includes two such variables it is possible to choose
coefficients which make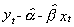 appear to be
stationary. But such an empirical result tells us little of the short run
relationship between yt and xt. In fact, if the two series
are both I(1) then we will often reject the hypothesis of no relationship between them
even when none exists. For there to be a long run relationship between the variables
they must be cointegrated. The following cases illustrate the discussion:
appear to be
stationary. But such an empirical result tells us little of the short run
relationship between yt and xt. In fact, if the two series
are both I(1) then we will often reject the hypothesis of no relationship between them
even when none exists. For there to be a long run relationship between the variables
they must be cointegrated. The following cases illustrate the discussion:
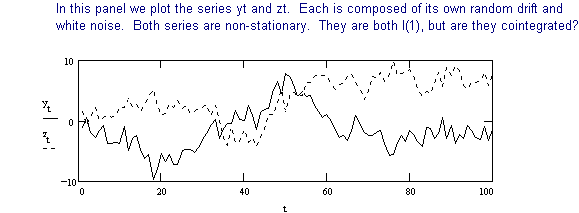
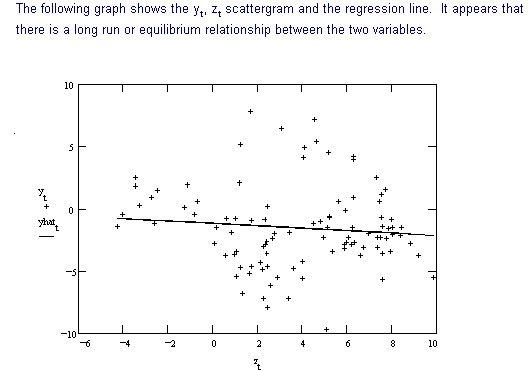
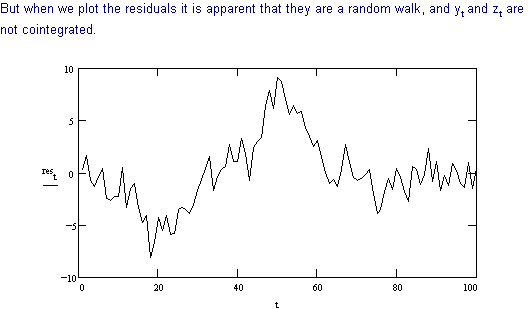
To detect cointegration we use the following procedure developed in the previous section.
Procedure:
1. Determine whether yt and xt are I(1). This is equivalent to
determining whether or not they contain unit roots.
2. Provided they are both I(1), estimate the parameters of the cointegrating relation 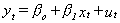 .
.
3. Test to see whether the least squares residual 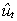 appears to be I(0) or not.
appears to be I(0) or not.
Historically, the standard fix-up for overcoming the possibly spurious relationship
between two variables has been to first difference each series and redo the regression.
This practice has raised the cry that 'valuable long-run information has been lost'.
The problem then is to find a way to work with two possibly nonstationary series in a
fashion that allows us to capture both short run and long run effects. In more
technical parlance, cointegration is the link between integrated processes and steady
state equilibrium.
For the purpose of illustration we will consider the simple model
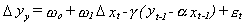
in which the error term has no MA part and the cointegrating parameter in
the error correction mechanism (ECM, the part in parentheses) is (1, -a).
In the no growth steady state we have 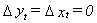 and
the equilibrium shows a long run proportionality between yt and xt
when both variables are measured in logarithms. That is,
and
the equilibrium shows a long run proportionality between yt and xt
when both variables are measured in logarithms. That is, 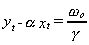 . Suppose that in the steady state there is a constant rate of growth, say
g. That is,
. Suppose that in the steady state there is a constant rate of growth, say
g. That is, 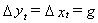 . Then the equilibrium
relationship is
. Then the equilibrium
relationship is 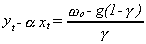 .
.
The procedure for estimating the parameters is to fit the error correction model after
having tested for unit roots and cointegration.
To help fix the ideas we consider an analogy. Sal Minella and her young puppy Spike
are seen staggering out of the Charlie Horse Saloon just as we arrive. Sal has had too
much to drink. Her movement away from the saloon is seen to be erratic. Puppies are
also prone to wander aimlessly; each new scent provides an impetus to go off in another
direction. Dog and owner are not connected by a leash, although Sal knows she owns a dog
and Spike will respond to his name.
Sal's meandering down the street can be modeled as a random walk along the real line, 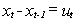 . The real line in this case can be taken to be a
narrow path leading away from the bar through an open field. On coming out of the
bar a short time later, our best prediction for Sal's current location is where we last
saw her. Because her movements are a random walk, the longer we have been in the bar
ourselves, the more likely it is that Sal has wondered far from where we last saw
her. She is as likely to be on the path as out in the middle of the field. If
the coefficient on xt-1, her last position, was less than one (in absolute
value) then she would tend to return to the path no matter how long we remained in the
bar.
. The real line in this case can be taken to be a
narrow path leading away from the bar through an open field. On coming out of the
bar a short time later, our best prediction for Sal's current location is where we last
saw her. Because her movements are a random walk, the longer we have been in the bar
ourselves, the more likely it is that Sal has wondered far from where we last saw
her. She is as likely to be on the path as out in the middle of the field. If
the coefficient on xt-1, her last position, was less than one (in absolute
value) then she would tend to return to the path no matter how long we remained in the
bar.
Similarly, Spike's wandering can also be modeled as a random walk along the real line, 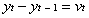 . This equation describes the puppy's random movement
from location to location along the path toward home. His movement is also a random walk,
so with the passage of time he is as likely to be somewhere on the path as out in the
field.
. This equation describes the puppy's random movement
from location to location along the path toward home. His movement is also a random walk,
so with the passage of time he is as likely to be somewhere on the path as out in the
field.
If in her stupor Sal notices that Spike is not at her side she will call his name.
In response he will trot closer to the source of his name. By the same token, Spike
will bark when he realizes that he has wandered off from his mistress and Sal will stagger
off in the direction of the bark. Hence we have a long run relationship which recognizes
the association between Sal and Spike: 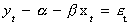 . So,
although xt and yt are both nonstationary, a linear combination of
them is stationary. Furthermore, Sal and Spike determine their next 'step' according to
the system of equations
. So,
although xt and yt are both nonstationary, a linear combination of
them is stationary. Furthermore, Sal and Spike determine their next 'step' according to
the system of equations
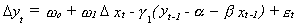
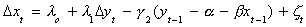
The series for the change in, say, Sal's position is determined by the extent to which she
and Spike have wandered far apart. In fact, Sal's next step closes the deviation
from long run equilibrium in the previous period by the amount g2.
Sal and Spike can be generalized to the following definition:
The components of the vector xt = (x1t, x2t, …, xnt)are
cointegrated of order (d,b), denoted by xt ~ CI(d,b), if
- All components of xt are I(d) and
- There exists a vector b = (b1, b2,…,bn) such that bxt is I(d-b), where b > 0.
Note b is called the cointegrating vector.
Points to remember:
- To make b unique we must normalize on one of the coefficients.
- All variables must be cointegrated of the same order. But, all variables of the same
I(d) are not necessarily cointegrated.
- If xt is nx1 then there may be as many as n-1 cointegrating vectors. The
number of cointegrating vectors is called the cointegrating rank.
An interpretation of cointegrated variables is that they share a common stochastic
trend. Consider
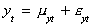
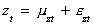
in which mit is a random walk and eit is white noise. If yt and zt
are cointegrated then we can write
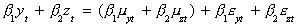
The term in parentheses must vanish. That is, up to some scalar b2/b1 the two
variables have the same stochastic trend. The remaining linear combination of the white
noise terms is itself white noise.
Given our notions of equilibrium in economics, we must conclude that the time paths of
cointegrated variables are determined in part by how far we are from equilibrium. That is,
if the variables wander from each other, there must be some way for them to get back
together, as in the Spike and Sal example. This is the notion of error correction.
EXAMPLE
rst: short term interest rate
rLt: long term interest rate
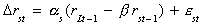
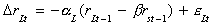
The eit are white noise. By
assumption Drit must be stationary, so the LHS
variables are I(0). The errors are necessarily I(0). Therefore, the two interest rates
must cointegrated of order CI(1,1).
- We could add lagged Drit to the RHS of both
equations without changing the interpretation of the model.
- With the added terms we would have a model similar to a vector autoregression (VAR).
However, if we were to estimate an unrestricted VAR then we would introduce a
misspecification error.
- as and aL can be thought of as speed of adjustment parameters.
- At least one of as and aL must be non-zero.
Let us explore the relationship between the error correction model (ECM) and the VAR.
Suppose we have the simple model
yt = a11yt-1 + a12zt-1
+ eyt
zt = a21yt-1 + a22zt-1 + ezt
We can write the model as
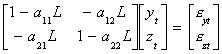
Using Cramer's Rule
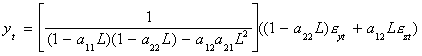
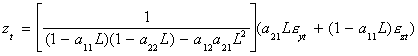
- Both variables have the same characteristic equation, in square brackets. By
multiplying through the equation for yt, say, by the inverse of [�] you
will get an ARMA representation. In order for the AR part to be stationary the roots
of {(1- a11L)(1-a22L)-a12a21L2}
must lie outside the unit circle.
- If the roots of Characteristic equation's (the fraction) polynomial in L (the lag
operator) lie inside the unit circle then both zt and yt are
stationary (see the first point) and cannot be cointegrated.
- Even if only 1 root of the characteristic equation lies outside the unit circle then
both variables are explosive, so cannot be CI(1,1).
- If both roots are unity then both variables are I(2)and cannot be CI(1,1).
- If a12 = a21 = 0 and a11 = a22 = 1 then both
variables are I(1), but do not have any long run relationship, so cannot be CI.
- For yt and zt to CI(1,1) one root must be 1 and the other must be
less than 1.
For this particular example we can show
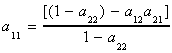
For cointegration either a12 or a21 must be non-zero
and the condition that the second root of the polynomial in L be more than 1 in absolute
value requires the following condition on the aij:
-1 < a22 and a12a21+a222 < 1
Now rewrite the system as
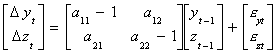
Our prior solution for a11 can be used to write
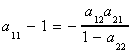
Make this substitution into the previous line
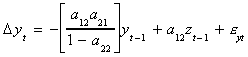
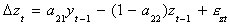
which can be rewritten as
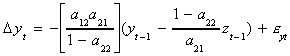
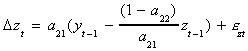
which is seen to be an ECM.
Implications:
- If in a VAR the variables are CI(1,1), then an ECM exists.
- If variables are cointegrated and we wish to estimate a VAR then we must impose
restrictions on the VAR coefficients.
- Suppose yt and zt are cointegrated. zt does not Granger
cause yt if no lagged values of Dzt-i
enter Dyt and if yt does not respond to
deviations from long run equilibrium.
Testing for cointegration
1. Test the variables for order of integration. They must both (all) be I(d).
2. Estimate the parameters of the long run relationship. For example,
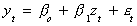
when yt and zt are cointegrated OLS is super
consistent. That is, the rate of convergence is T2 rather than just T in
Chebyshev's inequality.
3. Denote the residuals from step 2 as 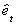 and fit the
model
and fit the
model
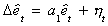
The null and alternate hypotheses are

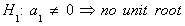
Interpretation: Rejection of the Null implies the residual is stationary.
If the residual series is stationary then yt and zt must be
cointegrated.
4. If you reject the null in step 3 then estimate the parameters of the ECM
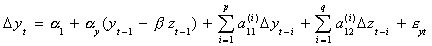
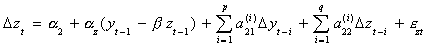
The terms in parentheses are the error correction terms. One uses the residuals from
step 2 in their place.
EXAMPLE
et: the price of foreign exchange in log form

pt: log of domestic price level
According to the purchasing power parity model (PPP) we should observe that the series
rt = et + pt* - pt
is stationary. In the earlier section on unit roots we observed that this
was not the case. As an alternative approach one might argue that the series {et
+ pt*} should be cointegrated with {pt}. Redefine
the foreign price level in dollar terms as ft = et + pt*.
Then by the PPP model there is a long run relationship
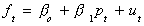
such that ut is stationary. Notice that now the
cointegrating vector between the three original variables is not (1,1,-1). Now the
cointegrating vector between ft and pt is
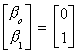
under a strict interpretation of the PPP model. But such a strict interpretation of
the PPP may be too restrictive.
1. The first step is to see that ft and pt are both I(1)
for each of the Bundesrepublik Deutschland (BRD), Japan (J) and Canada ( C) relative to
the U.S. If they were integrate of different orders then we could reject PPP immediately.
For each country the pairs are I(1). These results are not shown.
2. Fitting the PPP model to the US against BRD, J and C gives us the following result
on the slope coefficient, with standard errors in parentheses:
| |
BRD |
J |
C |
1960-1971 |
.666
(.03) |
.7361
(.015) |
1.081
(.02) |
1973-1986 |
.537
(.04) |
.894
(.03) |
.775
(.007) |
Under the strictest interpretation of the PPP things don't look good for the modelsince
the slope coefficients are clearly different from one.
3. Use the residuals from step 2 to check for unit roots. If ft and pt
are to be said to be cointegrated then the residual series must be stationary. We fit the
models
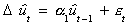
and
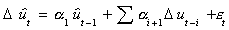
in order to test the hypothesis
Ho: a1=0, unit root, residual series not stationary, no
cointegration
H1: a1 not 0, no unit root in residual series, original variables
are cointegrated
We must reject the null hypothesis in order to find support for PPP.
We cannot use the usual Dickey Fuller tables since the data are a set of fitted residuals,
and at most t-2 of them are independent.
The set of estimates for a1 are
| |
BRD |
J |
C |
1960-1971 |
-.029
(-1.47) |
-.182
(-3.47) |
-.051
(-1.66) |
The numbers in parentheses are 't' statistics. Only for Japan can we reject the
null hypothesis.
Now construct an ECM for the Japan-US model
ft = .0012 - .1055 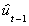
(4x10-4) (4.2x10-2)
pt = .00156 + .01114 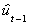
(3.3x10-4) (3.17x10-3)
The numbers in parentheses are standard errors and 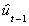 are the residuals from
are the residuals from 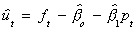 . For these results, as the
foreign price level rises above the domestic price level we will see ft<0
next period. If the foreign price level rises above the domestic price level we will
see pt>0 next period.
. For these results, as the
foreign price level rises above the domestic price level we will see ft<0
next period. If the foreign price level rises above the domestic price level we will
see pt>0 next period.
Note the asymmetry in the data. The speed of adjustment is significant for Japan, but not
for the US. At the same time the speed of adjustment is 10x that in the US. This is
consistent with the size of the US relative to Japan for the period.
You can dowload another example (a WORD file)for money
and income that has both the RATS program and the output. You can take a look at the
data (an EXCEL file) also.